Brainformers: Trading Simplicity for Efficiency
2306.00008
81
0
🧪
Abstract
Transformers are central to recent successes in natural language processing and computer vision. Transformers have a mostly uniform backbone where layers alternate between feed-forward and self-attention in order to build a deep network. Here we investigate this design choice and find that more complex blocks that have different permutations of layer primitives can be more efficient. Using this insight, we develop a complex block, named Brainformer, that consists of a diverse sets of layers such as sparsely gated feed-forward layers, dense feed-forward layers, attention layers, and various forms of layer normalization and activation functions. Brainformer consistently outperforms the state-of-the-art dense and sparse Transformers, in terms of both quality and efficiency. A Brainformer model with 8 billion activated parameters per token demonstrates 2x faster training convergence and 5x faster step time compared to its GLaM counterpart. In downstream task evaluation, Brainformer also demonstrates a 3% higher SuperGLUE score with fine-tuning compared to GLaM with a similar number of activated parameters. Finally, Brainformer largely outperforms a Primer dense model derived with NAS with similar computation per token on fewshot evaluations.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Transformers are a key component in recent advances in natural language processing and computer vision.
- The standard Transformer architecture alternates between feed-forward and self-attention layers.
- This paper investigates more complex Transformer block designs that can be more efficient.
Plain English Explanation
Transformers are a type of machine learning model that have been very successful in tasks like understanding natural language and analyzing images. The standard Transformer design uses a simple pattern of alternating between two types of layers - feed-forward layers and self-attention layers.
This paper explores the idea that more complex Transformer block designs, with a diverse set of layer types, could potentially be more efficient and effective than the standard approach. The researchers developed a new Transformer block called the Brainformer that includes a variety of layers like sparse feed-forward, dense feed-forward, attention, and different normalization and activation functions.
The key finding is that the Brainformer consistently outperforms state-of-the-art dense and sparse Transformer models in terms of both quality of results and computational efficiency. For example, a Brainformer model with 8 billion parameters trains 2x faster and runs 5x faster per step compared to a similar-sized GLaM Transformer. The Brainformer also achieved a 3% higher score on a benchmark language understanding task compared to GLaM.
Overall, the paper suggests that more flexible and diverse Transformer architectures, like the Brainformer, can lead to significant performance improvements over the standard Transformer design.
Technical Explanation
The researchers start by noting that the standard Transformer architecture, which alternates between feed-forward and self-attention layers, may not be the most efficient or optimal design. They hypothesize that using a more complex block with a diverse set of layer primitives could lead to better performance.
To test this, they develop a new Transformer block called the Brainformer. The Brainformer consists of several different layer types, including:
- Sparsely gated feed-forward layers
- Dense feed-forward layers
- Attention layers
- Various forms of layer normalization
- Different activation functions
The researchers evaluate the Brainformer against state-of-the-art dense and sparse Transformer models like GLaM and a Primer model derived through neural architecture search. They find that the Brainformer consistently outperforms these models in terms of both quality of results and computational efficiency.
Specifically, a Brainformer model with 8 billion activated parameters demonstrates 2x faster training convergence and 5x faster step time compared to its GLaM counterpart. On the SuperGLUE language understanding benchmark, the Brainformer also achieves a 3% higher score compared to GLaM with a similar number of activated parameters. The Brainformer further outperforms the NAS-derived Primer model on few-shot evaluation tasks.
Critical Analysis
The paper provides a compelling argument that more complex and heterogeneous Transformer block designs can lead to significant performance improvements over the standard alternating feed-forward/self-attention approach. The development and successful evaluation of the Brainformer block is a noteworthy contribution.
However, the paper does not provide much insight into why the Brainformer architecture is so effective. The authors suggest that the diversity of layer types gives the model more expressive power, but do not delve deeper into the underlying reasons. More analysis of the model's internal dynamics and how the different components interact could strengthen the technical understanding.
Additionally, the paper only evaluates the Brainformer on a limited set of tasks and datasets. While the results are promising, further testing on a wider range of applications would help validate the generalizability of the findings. Comparisons to other recent Transformer variants, such as NvFormer or Multi-Level Transformer, could also provide additional context.
Overall, this paper makes an important contribution in demonstrating the potential benefits of more complex Transformer block designs. However, further research is needed to fully understand the reasons behind the Brainformer's success and explore its broader applicability.
Conclusion
This paper investigates an alternative approach to the standard Transformer architecture, which typically alternates between feed-forward and self-attention layers. By developing a more complex Transformer block called the Brainformer, the researchers show that incorporating a diverse set of layer types can lead to significant improvements in both model quality and computational efficiency compared to state-of-the-art dense and sparse Transformer models.
The key takeaway is that the flexibility and expressiveness granted by heterogeneous Transformer blocks may be a fruitful direction for further research and development in this area. As Transformer models continue to grow in scale and importance across natural language processing, computer vision, and other domains, innovations in architectural design could unlock new levels of performance and capability.
Related Papers
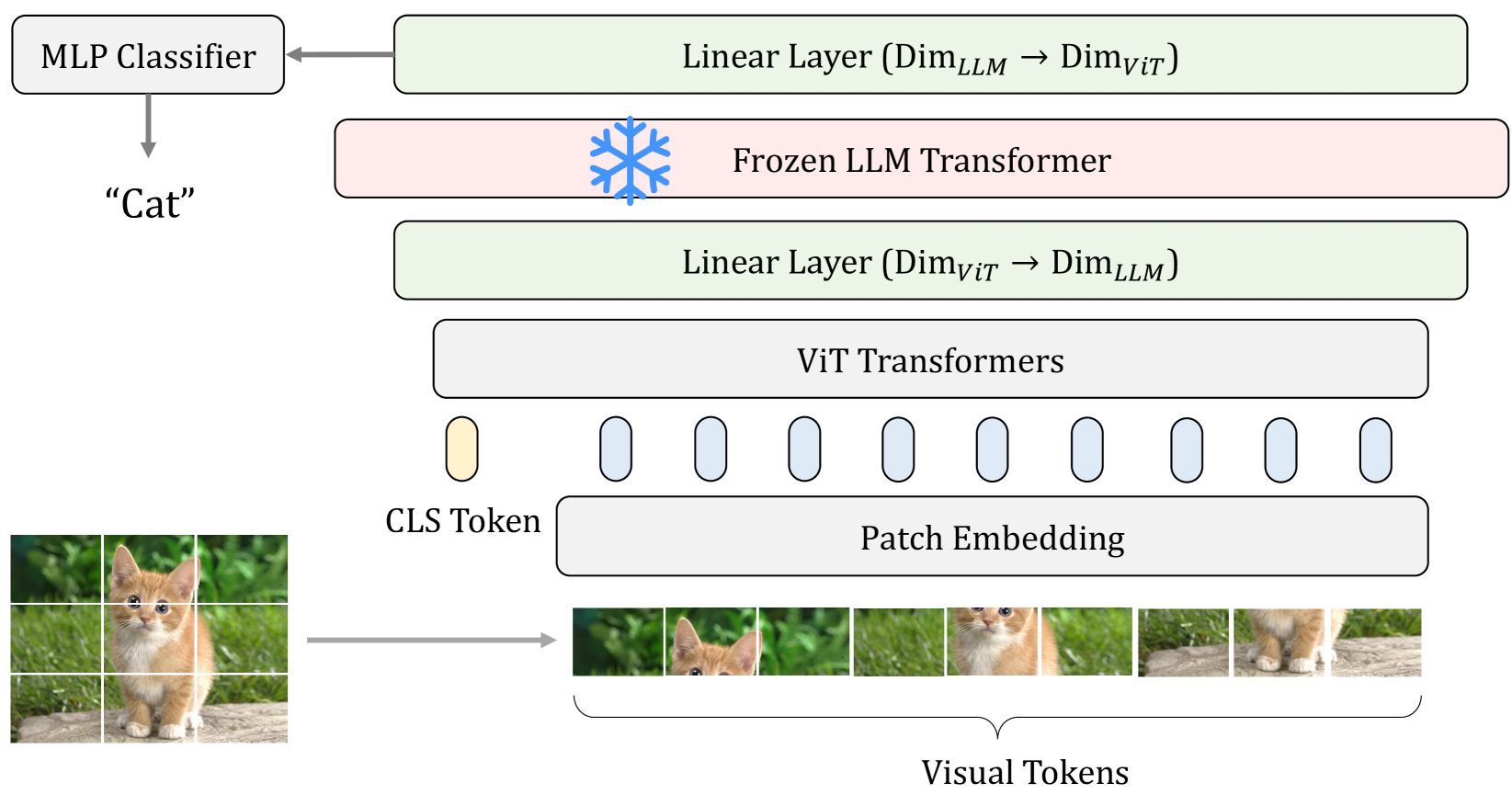
Frozen Transformers in Language Models Are Effective Visual Encoder Layers
Ziqi Pang, Ziyang Xie, Yunze Man, Yu-Xiong Wang
0
0
This paper reveals that large language models (LLMs), despite being trained solely on textual data, are surprisingly strong encoders for purely visual tasks in the absence of language. Even more intriguingly, this can be achieved by a simple yet previously overlooked strategy -- employing a frozen transformer block from pre-trained LLMs as a constituent encoder layer to directly process visual tokens. Our work pushes the boundaries of leveraging LLMs for computer vision tasks, significantly departing from conventional practices that typically necessitate a multi-modal vision-language setup with associated language prompts, inputs, or outputs. We demonstrate that our approach consistently enhances performance across a diverse range of tasks, encompassing pure 2D and 3D visual recognition tasks (e.g., image and point cloud classification), temporal modeling tasks (e.g., action recognition), non-semantic tasks (e.g., motion forecasting), and multi-modal tasks (e.g., 2D/3D visual question answering and image-text retrieval). Such improvements are a general phenomenon, applicable to various types of LLMs (e.g., LLaMA and OPT) and different LLM transformer blocks. We additionally propose the information filtering hypothesis to explain the effectiveness of pre-trained LLMs in visual encoding -- the pre-trained LLM transformer blocks discern informative visual tokens and further amplify their effect. This hypothesis is empirically supported by the observation that the feature activation, after training with LLM transformer blocks, exhibits a stronger focus on relevant regions. We hope that our work inspires new perspectives on utilizing LLMs and deepening our understanding of their underlying mechanisms. Code is available at https://github.com/ziqipang/LM4VisualEncoding.
5/7/2024
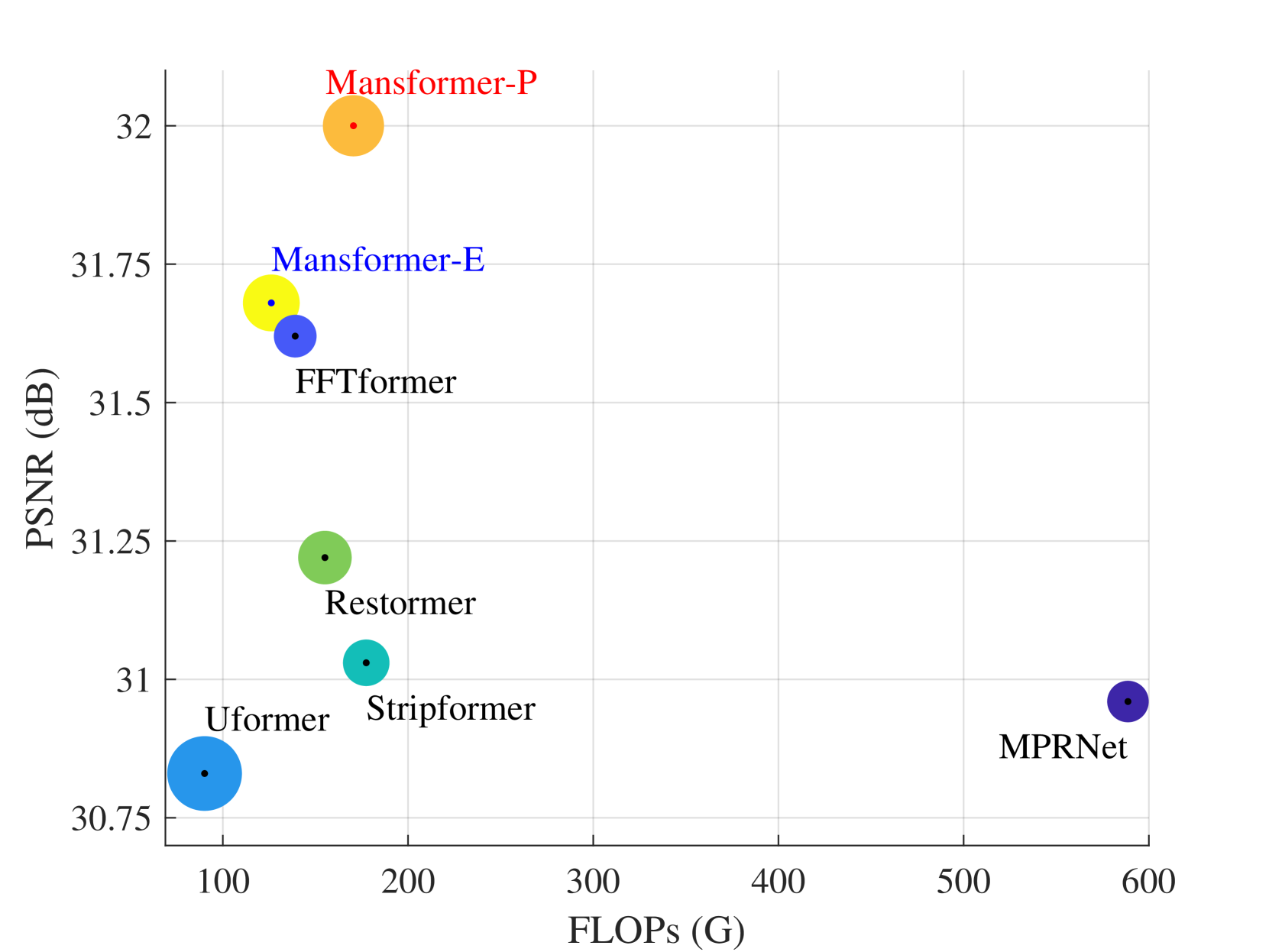
Mansformer: Efficient Transformer of Mixed Attention for Image Deblurring and Beyond
Pin-Hung Kuo, Jinshan Pan, Shao-Yi Chien, Ming-Hsuan Yang
0
0
Transformer has made an enormous success in natural language processing and high-level vision over the past few years. However, the complexity of self-attention is quadratic to the image size, which makes it infeasible for high-resolution vision tasks. In this paper, we propose the Mansformer, a Transformer of mixed attention that combines multiple self-attentions, gate, and multi-layer perceptions (MLPs), to explore and employ more possibilities of self-attention. Taking efficiency into account, we design four kinds of self-attention, whose complexities are all linear. By elaborate adjustment of the tensor shapes and dimensions for the dot product, we split the typical self-attention of quadratic complexity into four operations of linear complexity. To adaptively merge these different kinds of self-attention, we take advantage of an architecture similar to Squeeze-and-Excitation Networks. Furthermore, we make it to merge the two-staged Transformer design into one stage by the proposed gated-dconv MLP. Image deblurring is our main target, while extensive quantitative and qualitative evaluations show that this method performs favorably against the state-of-the-art methods far more than simply deblurring. The source codes and trained models will be made available to the public.
4/10/2024
A Multi-Level Framework for Accelerating Training Transformer Models
Longwei Zou, Han Zhang, Yangdong Deng
0
0
The fast growing capabilities of large-scale deep learning models, such as Bert, GPT and ViT, are revolutionizing the landscape of NLP, CV and many other domains. Training such models, however, poses an unprecedented demand for computing power, which incurs exponentially increasing energy cost and carbon dioxide emissions. It is thus critical to develop efficient training solutions to reduce the training costs. Motivated by a set of key observations of inter- and intra-layer similarities among feature maps and attentions that can be identified from typical training processes, we propose a multi-level framework for training acceleration. Specifically, the framework is based on three basic operators, Coalescing, De-coalescing and Interpolation, which can be orchestrated to build a multi-level training framework. The framework consists of a V-cycle training process, which progressively down- and up-scales the model size and projects the parameters between adjacent levels of models via coalescing and de-coalescing. The key idea is that a smaller model that can be trained for fast convergence and the trained parameters provides high-qualities intermediate solutions for the next level larger network. The interpolation operator is designed to break the symmetry of neurons incurred by de-coalescing for better convergence performance. Our experiments on transformer-based language models (e.g. Bert, GPT) as well as a vision model (e.g. DeiT) prove that the proposed framework reduces the computational cost by about 20% on training BERT/GPT-Base models and up to 51.6% on training the BERT-Large model while preserving the performance.
4/15/2024
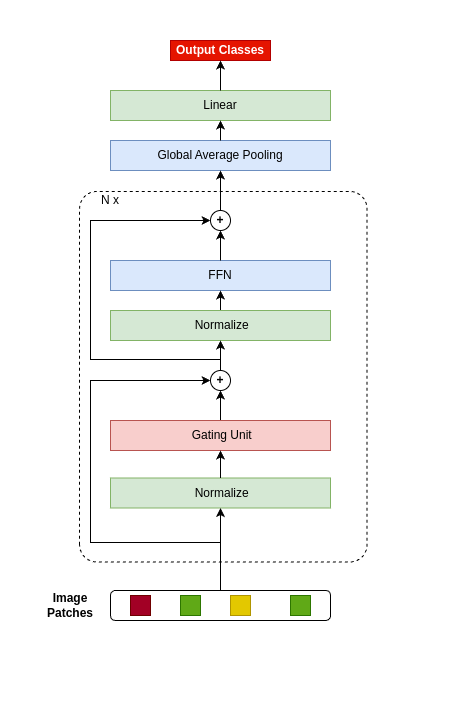
NiNformer: A Network in Network Transformer with Token Mixing Generated Gating Function
Abdullah Nazhat Abdullah, Tarkan Aydin
0
0
The Attention mechanism is the main component of the Transformer architecture, and since its introduction, it has led to significant advancements in Deep Learning that span many domains and multiple tasks. The Attention Mechanism was utilized in Computer Vision as the Vision Transformer ViT, and its usage has expanded into many tasks in the vision domain, such as classification, segmentation, object detection, and image generation. While this mechanism is very expressive and capable, it comes with the drawback of being computationally expensive and requiring datasets of considerable size for effective optimization. To address these shortcomings, many designs have been proposed in the literature to reduce the computational burden and alleviate the data size requirements. Examples of such attempts in the vision domain are the MLP-Mixer, the Conv-Mixer, the Perciver-IO, and many more. This paper introduces a new computational block as an alternative to the standard ViT block that reduces the compute burdens by replacing the normal Attention layers with a Network in Network structure that enhances the static approach of the MLP Mixer with a dynamic system of learning an element-wise gating function by a token mixing process. Extensive experimentation shows that the proposed design provides better performance than the baseline architectures on multiple datasets applied in the image classification task of the vision domain.
4/26/2024